Qwen ha reso open source la serie Qwen2.5-Coder, che combina potenza, diversità e praticità. Con l’obiettivo di sviluppare sempre più avanzati modelli di linguaggio per il codice, Qwen2.5-Coder offre prestazioni di alto livello nel settore, a partire dalle dimensioni del modello (0,5B a 32B parametri).
Caratteristiche Principali della Serie Qwen2.5-Coder
Potenza
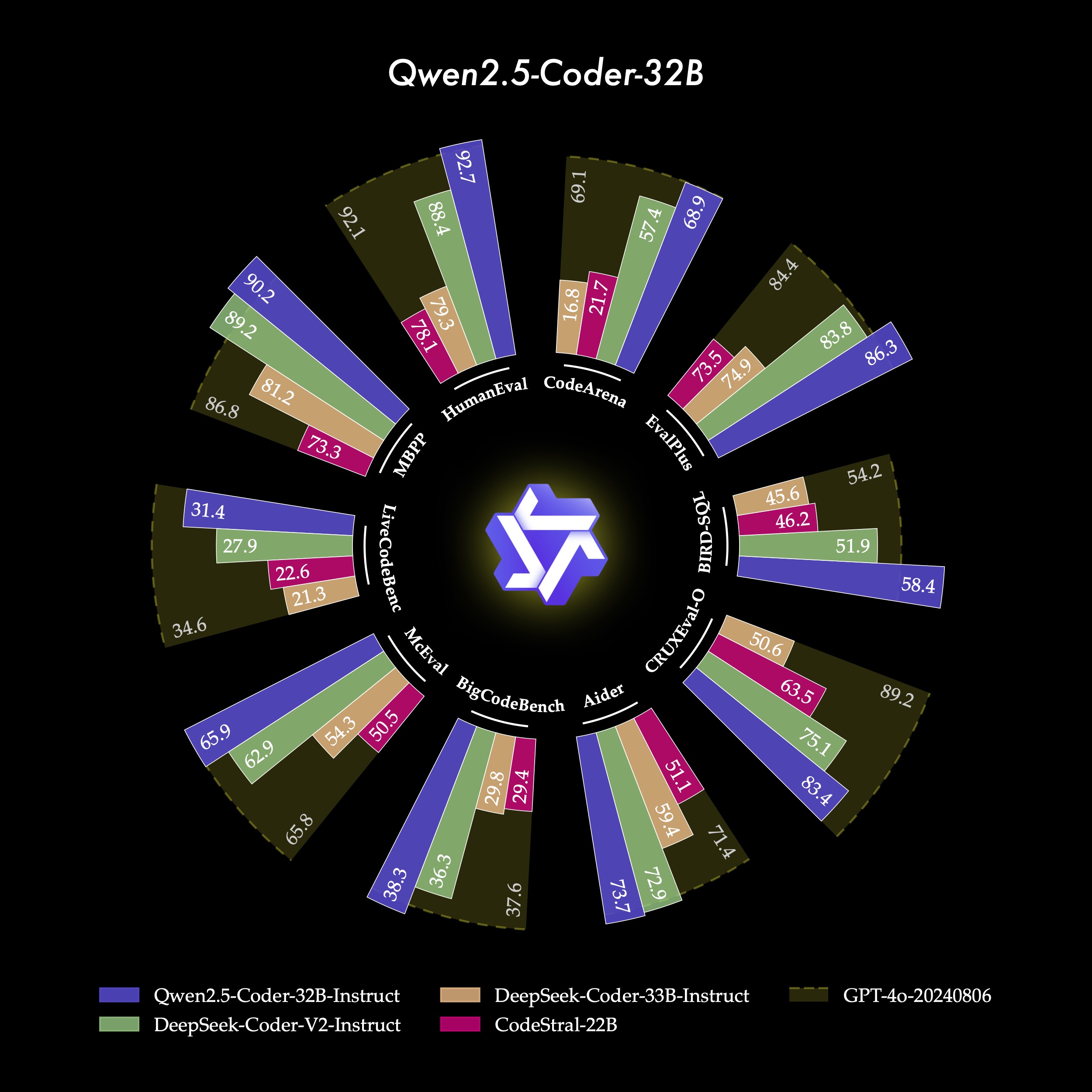
Qwen2.5-Coder-32B-Instruct è attualmente il modello open-source di riferimento per capacità di codifica, comparabile a GPT-4o. Mostra competenze avanzate non solo nella codifica ma anche nelle capacità matematiche e generali.
Diversità
Questa serie comprende vari modelli, disponibili in diverse dimensioni (0.5B, 3B, 14B, 32B) per soddisfare le esigenze di diversi sviluppatori.
Praticità
Qwen2.5-Coder è progettato per supportare scenari pratici come assistenti di codifica e integrazioni in ambienti reali. La sua vasta copertura di lingue di programmazione e funzionalità di riparazione del codice lo rende uno strumento versatile.
Qwen2.5-Coder: Una Risorsa per gli Sviluppatori
In un mondo dove l’automazione della programmazione è sempre più importante, Qwen2.5-Coder risponde alle esigenze di efficienza e adattabilità con una serie di modelli open-source. Basato su una struttura avanzata e un tokenizer ampliato, consente un’accuratezza elevata nella generazione del codice e nella risoluzione di problemi complessi.
Generazione del Codice
Qwen2.5-Coder-32B-Instruct eccelle nella generazione di codice, dimostrandosi leader nei benchmark (EvalPlus, LiveCodeBench) e mantenendo un livello competitivo con modelli come GPT-4o.
Riparazione del Codice
Con un punteggio di 73,7 su Aider, Qwen2.5-Coder-32B-Instruct rende più facile la correzione degli errori, migliorando la produttività degli sviluppatori.
Ragionamento del Codice
Questa serie mostra capacità di ragionamento avanzate, prevedendo correttamente input e output del codice su vari benchmark di logica e comprensione, come MdEval.
Supporto Multilingua
Qwen2.5-Coder gestisce oltre 40 linguaggi di programmazione, rendendolo una risorsa efficace anche per chi si cimenta in nuove lingue. Con punteggi elevati nei benchmark, si distingue in linguaggi come Haskell e Racket, grazie a un processo di pre-addestramento mirato.
Allineamento con le Preferenze Umane
Il modello è ottimizzato per l'allineamento alle preferenze umane, come dimostrato dal benchmark interno Code Arena, dove supera in performance altri modelli open-source.
Dettagli Tecnici
Pre-addestramento: Qwen2.5-Coder utilizza un vasto corpus di 5,5 trilioni di token, includendo repository pubblici e dataset sintetici creati da CodeQwen1.5. Questo assicura la generazione di codice eseguibile e riduce il rischio di risultati non corretti.
Performance Avanzate: Qwen2.5-Coder si distingue nei benchmark come HumanEval e BigCodeBench, garantendo accuratezza in numerosi linguaggi di programmazione e supportando contesti estesi fino a 128k token.
Scalabilità e Accessibilità
Con diverse dimensioni (da 0.5B a 32B) e formati quantizzati come GPTQ e AWQ, Qwen2.5-Coder risponde a diverse esigenze computazionali, rendendosi accessibile a chi non ha risorse di alto livello.
Esempio
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "scrivi un algoritmo di ordinamento rapido."Configurazione per Lunghe Sequenze
Il modello supporta configurazioni per input fino a 32,768 token grazie alla tecnica YaRN, che ne ottimizza le prestazioni su testi estesi.
Maggiori informazioni
Per maggiori dettagli e risorse approfondite su Qwen2.5-Coder, è possibile consultare la pagina dedicata su Hugging Face, dove sono disponibili i modelli e le istruzioni per il loro utilizzo. Ulteriori informazioni, inclusi i dettagli tecnici e le novità sui miglioramenti della serie, sono presenti nel blog ufficiale di Qwen.